

Apache Kafka
- Open source
- Distributed
- Event streaming
- Creating real-time stream
- Processing real-time stream
- Messaging platform
To learn in more detail, please refer the Introduction to Apache Kafka.
Apache Kafka Architecture
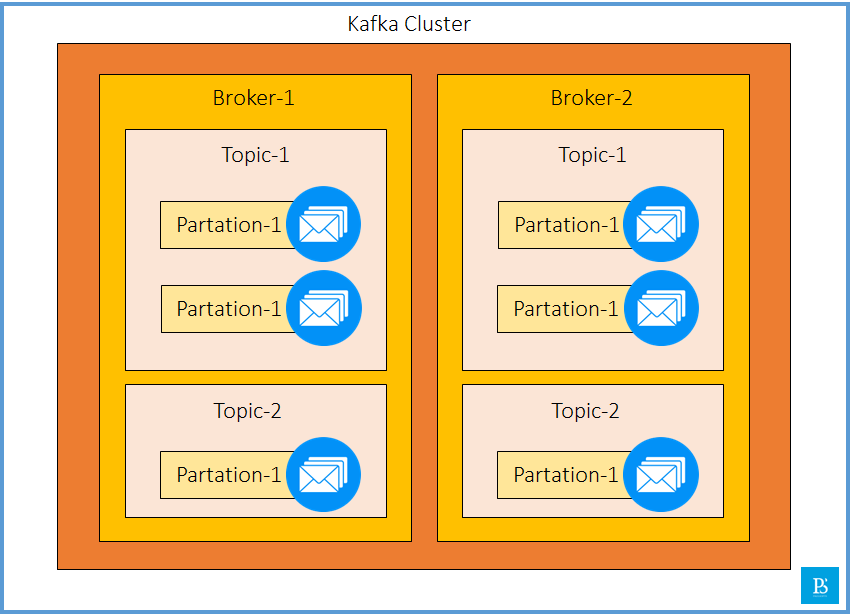
The ecosystem of Apache Kafka consists of Kafka Clusters, these clusters contain Brokers, the broker contains Topics and the topics contain Partitions. Given below is the Kafka architecture diagram, which provides a complete picture of Kafka architecture.

Components of Apache Kafka
- Producer
- Consumer
- Cluster
- Broker
- Topic
- Partition
- Offset
- Zookeeper
- Consumer Group
We will learn about each components of Apache Kafka Ecosystem in detail.
Kafka Producer
Producers are the applications or the source of data that publish the messages or events to the Kafka-Topics. Basically, they send the message to the Brokers, specifying the target topic.
Kafka Consumers
Consumers are the receiver which is responsible for consuming the messages or events. They subscribe the to the specific topics and reads data from the partitions. Kafka make sure that each message in the partition are consumed in order.

Kafka Cluster
Clusters are the group of computers or servers working together to achieve a common purpose. It is a common term in distributed computing systems. As Kafka is also a distributed system, it can have multiple Server inside a single Kafka-Cluster. Below, we can see that the Kafka Cluster architecture can have multiple brokers. i.e., Kafka servers.
Kafka Broker
Brokers are the Kafka server instances that are responsible for storing and managing the message streams. It contains subsets of topics and partitions. If an application publishes huge volumes of data, it may be possible that such a huge volume of data is not handled by a single broker, and hence, we can also have multiple brokers within a single cluster.
Kafka Topic
Topic is a logical channel or a category of a message, to which producers send message streams. It is divided into partitions, which helps in Parallelisms and Scalability. Each message published to a topic is appended to one of its partitions.
In other words, topics in Kafka-Ecosystem are similar to tables in the database. For example, In database, employee_table contains employee-related information, payment_table contains payment-related data. Similarly, In Kafka, employee_topic contains employee-related data streams.
Kafka Partitions
Partitions are the log file that stores a sequence of messages. Each message, published to Kafka topics, is stored in partitions in a sequential order and an offset is assigned to each message.
Partitions in Kafka helps in better performance and high availability. As we break the topic into multiple partitions, when producers publish huge volumes of data, each of partitions concurrently accepts the message data that improve the performance, and if any partition goes down, other partitions will be available to handle the load.
Kafka Offset
Offset is a unique identifier, which is assigned to each message within a partition. As soon as the message arrives to the partitions, an offset is assigned to the message. It is used to keep track of the messages that are consumed by the consumer. For example, if after reading few messages, the consumer goes down and after a while when it comes back online, this offset will help the consumer to know, from where the consumer needs to consume the messages.

Kafka Zookeeper
As we know, Kafka is a distributed system, and it uses Zookeeper for coordination and to track the status of Kafka cluster nodes. It also helps to keep track of Kafka topics, partitions, offsets, etc.
As of Kafka 2.8.0, Kafka is moving away from the dependency on Zookeeper for metadata management and building its own self-managed metadata model.
Kafka Consumer Group
As the name suggests, a consumer group is a group of two or more consumers combined together to share the workload for efficiency.
For example, if one consumer is consuming data from multiple partitions, it may reduce performance because there is no concurrency. In order to overcome this issue, we create groups of consumers so that we can rebalance the load. As we can see in the below diagram, all three consumers are reading concurrently from the topics, which will improve performance.
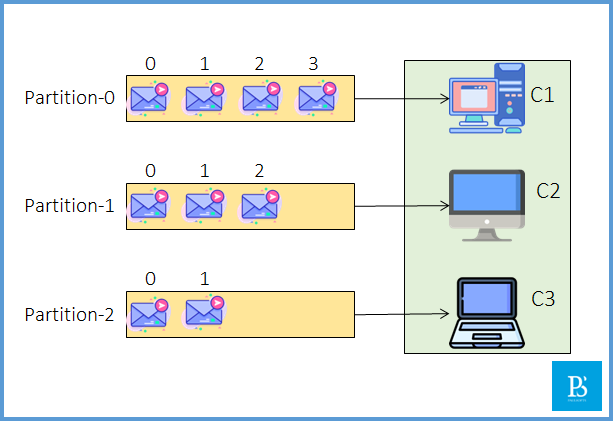
Note: The consumer-partition order is not specific or guaranteed, which means any consumer can read from any partition; this will be decided by the coordinator (zookeeper).
Consumer Rebalancing
Above, we have 3 consumers and 3 partitions. They are talking to each other; if we add one more consumer, say C4, it will remain ideal as there is no work for it. Since all 3 partitions are assigned to 3 different consumers, there is no partition left for C4, so it will sit ideal. But as soon as any consumer goes down, it will get a chance to connect to the partition. This is called consumer rebalancing.