

What is Apache Kafka?
Apache Kafka is an open-source distributed event streaming platform that is designed for high-throughput, fault-tolerant, and scalable real-time data streaming and processing. In other words, it is like a communication system that helps different parts of computer systems exchange data and information using the publish-subscribe model.
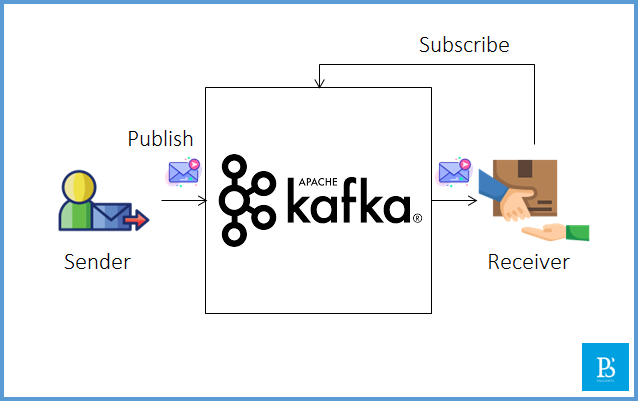
In the above picture, we can see that as the sender sends a message, it goes to the Kafka server, where the receiver has subscribed to the sender’s topic to receive the message. For example, if we assume YouTube as the Kafka server, the creator publishes a video, and the subscribers of that creator receive notifications for the video.
What is Kafka used for?
Let us understand why we need Apache Kafka. As it is a communication (messaging or notification) system, we can easily communicate using REST APIs, sockets, etc. Then why do we need Kafka? In order to understand this, we will analyze a real-life use case of Apache Kafka.
Example
Let’s take an example of the live tracking of a food delivery app, Zomato. In this application, a customer places an order, and the delivery boy picks up the order. The customer can track the delivery boy to check his order status. i.e., exactly where it arrived.
REST API Implementation
We can use the REST API to implement the above scenario. As the delivery person picks up the order, he will update the status. We can use the Rest API to update the database server, which is further consumed by the customer to check the status. In a similar way, as the delivery person starts moving towards the customer, we can use a fixed time interval to update the status, which will be consumed by the customer.
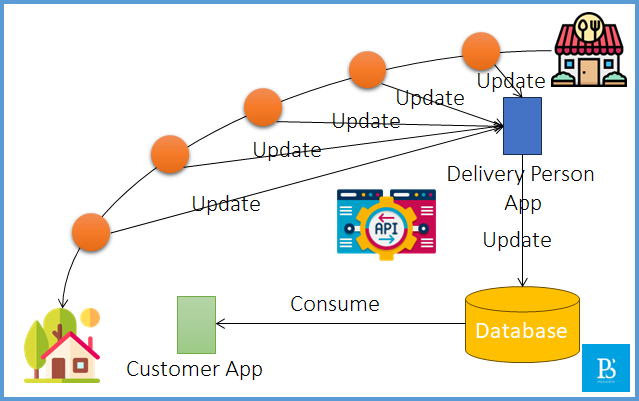
Let’s discuss the problems with the above approach:
- In order to get the live tracking of the delivery person, we need to perform a large number of database operations (Delivery Person: Write and Customer: Read).
- The database throughput is not too large, and multiple read and write operations lead to database crashes.
- For example, say it took 10 minutes for the delivery person to reach the customer on a particular single-route order. If we perform database operations every second for a live update (in real-time, a live update even took milliseconds), We need to perform 10 * 60 = 600 write and read operations, which is a total of 1200 database operations for a single customer. In a similar way, we can have 100s or 1000s of customers, which is definitely going to crash our database server.
Apache Kafka Implementation
If we implement our example using Kafka, we can eliminate the huge number of database operations. In this implementation, the delivery person’s app will publish the live update on the Kafka topic, and as the customer places the order, his application subscribes to that particular topic. As the status changes for the delivery person, the customer will automatically get the updated status in real time.

After the food delivery is completed, we can perform a batch operation to update the complete order details for order history and other information.
Benefits of Apache Kafka
Apache Kafka has a large number of benefits. A few of them are mentioned below:
- High Throughput: Kafka can handle huge volumes of data streams and events (requests and responses) per second, which makes it suitable for real-time data processing and analysis.
- Scalability: Apache Kafka can be easily scaled (horizontal scale), which gives it the capability to handle massive amounts of data traffic. We can scale it by adding more brokers to the clusters.
- Fault Tolerance: Apache Kafka is a distributed system. We can use replication to handle fault tolerance. It involves creating multiple copies (replica) and distributing them over different nodes. The leader nodes server the request. In case something happens with the leader node, any other node is appointed as leader and starts serving the requests.
- Durability: Because of the data replication over different nodes, Kafka is a durable system. Even in the event of hardware failure, data remains available.